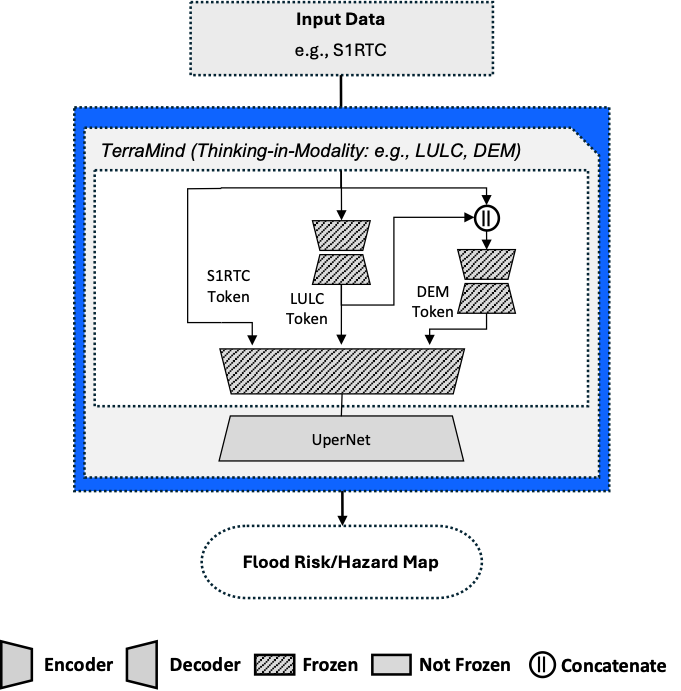
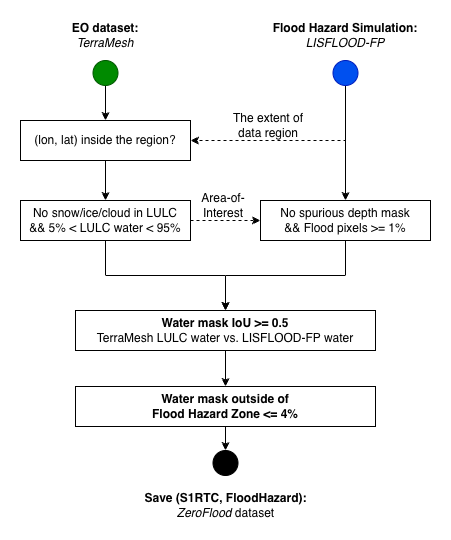
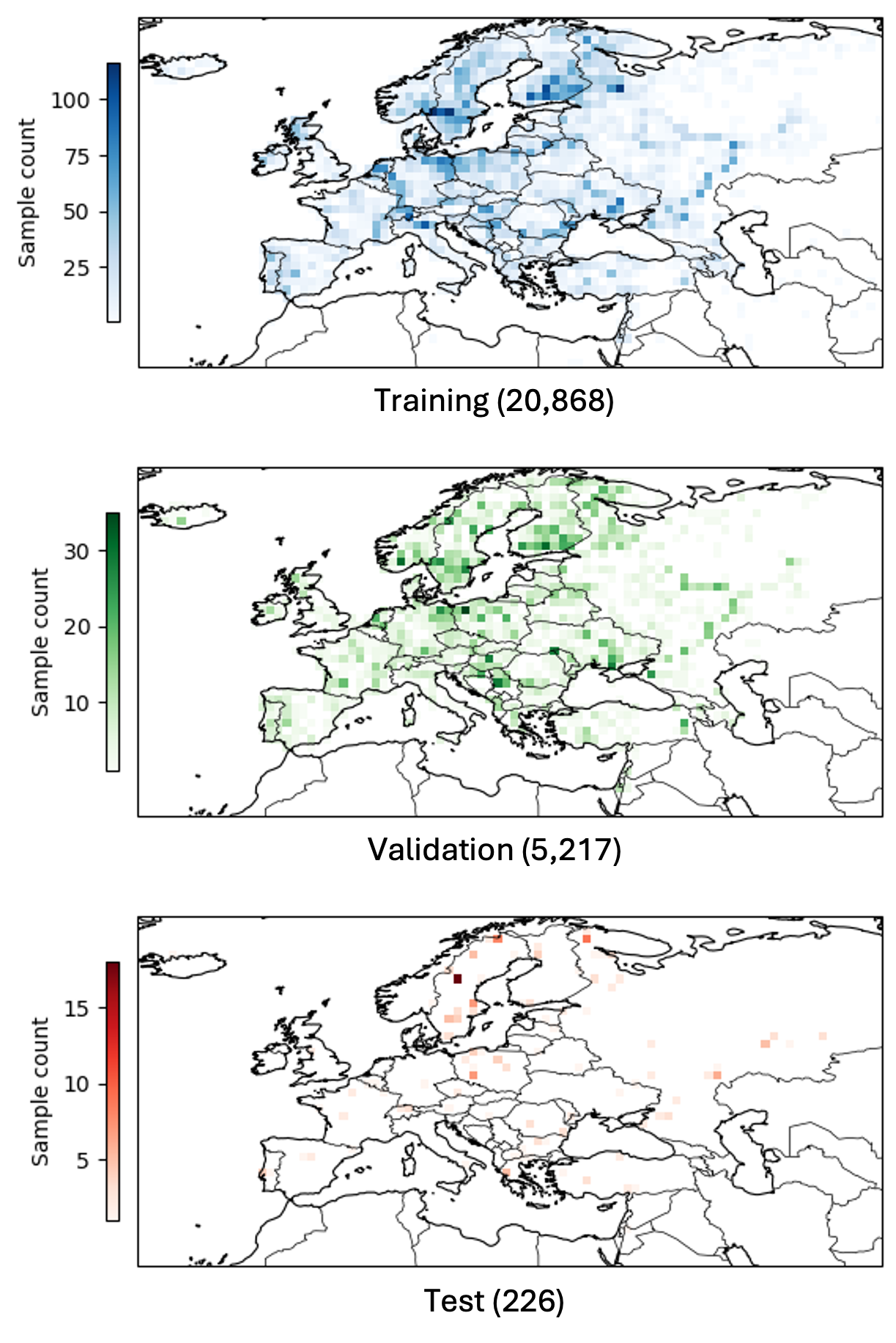
S1RTC input
| Model | F1 | Recall | Precision |
|---|---|---|---|
| UNet | 84.66 | 81.00 | 88.67 |
| ViT | 84.64 | 81.46 | 88.08 |
| SSL4EO-MAE | 85.23 | 81.39 | 89.44 |
| CROMA | 83.63 | 79.72 | 87.95 |
| DOFA | 86.90 | 84.80 | 89.11 |
| TerraMind | 88.36 | 86.77 | 90.02 | TerraMind-TiM-l | 89.12 | 88.45 | 89.80 |
| TerraMind-TiM-ds | 88.82 | 87.62 | 90.05 |
| TerraMind-TiM-dsl | 88.54 | 87.53 | 89.57 |
Evaluation results of the ZeroFlood model using S1RTC as the input modality. Tokens generated by the Thinking-in-Modalities (TiM) process are denoted as: s (S2L2A), l (LULC), and d (DEM). The highest value in each column is highlighted in bold.